
EVERYONE CAN DEPLOY!
How we used deployment automation to get to true continuous delivery
February 24th, 2022 / Christian Müllenhagen

Over the course of several months, we completely changed the way we deploy code to production in one of our largest platform projects. By heavily automating our deployments, we were able to implement true continuous delivery. Now, virtually anyone can deploy code to production – from developers to product owners and client stakeholders. And it’s not just our deployments that have gotten more stable – the quality of our software has increased as well.
Remember when you last felt queasy before deploying a feature to production? And when you were anxiously thinking about all the unintended consequences and fixes you would need to implement afterwards? We sure do. In fact, sometimes it still makes us restless. Yet several months ago, we set out on a journey to automate deployment and make things much easier and reliable for everyone.
Our starting situation was not optimal, despite having a fairly advanced deployment set-up with continuous integration and an intricate deployment pipeline in place. The system consisted of manual deployments with manual checks carried out by a small number of people, who were actually able to deploy code. Most developers didn't deploy themselves, so they didn't care about how the features they developed were going to be deployed. To avoid incidences close to weekends, deployments were allowed only until Thursday mornings at the very latest. Of course, we always made sure to document deployed tasks in order to make what had been deployed as transparent as possible for our team's product owner and stakeholders.
The end-result, though, was always the same: our team accumulated large batches of code to deploy at once. This meant insecurity was always highest during and after deployment itself – the more you deploy at once, the more can go wrong. Needless to say, something had to change.
Stage 1: Increased transparency in deployment process
The first thing we tackled was making the deployment process more transparent in general for everyone involved. To do so, we created a clear documentation for the process itself, and shared it internally so everyone on the team would be able to access it. This included a checklist of seven main steps from preparation to stage and live deployments, as well as explicit instructions on how to deploy and what to do in certain situations, such as hotfixes or rollbacks.
“Having large batches of code to deploy meant insecurity was always highest during and after deployment. The more you deploy at once, the more can go wrong.”
As a result, deploying became less dependent upon specific people. More team members were able to deploy by themselves, because the steps to follow were readily available. This meant we were able to streamline deployment and share the load. More standardization increased our peace of mind. Plus: it decreased our “lottery factor” significantly – if a key person were to win the lottery and stop working, we would still be able to manage deployments in our project.
Still, people struggled with deployment. A lot. This is mainly because they didn’t have to do it very often: imagine doing one deployment per day with a team of eight to ten developers, then each developer only has to deploy about once per week at maximum. Not a great way to make everyone comfortable with the process.

Stage 2: Deployment via command line tool, monitoring and alerting
Yet people following a set of standardized steps does not actually ensure that everyone always carries them out correctly. The only way to prevent human error is through automation. So, we began automating our deployments in order to reduce error-proneness and raise stability. Gradually, we removed manual steps in our deployment process and replaced them with a script. From now on, a command line tool would start to take the heavy load. This was an ongoing task we carried out step-by-step, pulling each of the points from our central deployment documentation and steadily extending the command line tool.
“The only way to prevent human error is through automation.”
We also implemented monitoring via NewRelic and Grafana. Instead of sending status messages via Slack, filling the release sheet and moving the deployed Jira tickets by hand, all of this was done by scripts. We set up specific thresholds, at which errors triggered our alert system, for example if an error persisted over a set percentage of page visits or timespan. All it took from here on out is "make deploy".
This resulted in a highly dynamic deployment situation. The number of deployments per week (even per day) increased dramatically with overall much smaller batches to deploy at a time. Standardization increased even further, as room for individual interpretation got smaller and smaller the more we integrated into the script. Finally, we needed much less time and effort for individual deployments. We felt so sure about the process that we now also started deploying on Fridays.
Stage 3: “PO deployment”
And thus, we arrive at stage three. After months of great service, we are now at a point where we have retired even the trusted command line tool we had steadily extended. After all, the command line is generally only accessible to developers.
So, we replaced the script that we used to replace ourselves… with a button. We moved all the former implementation to run directly in the deployment pipeline on Jenkins. Now, there is simply a "RUN" button, accessible to everyone, with which you can execute deployments. Of course, everything we did up to this point prepared us for this step. A prerequisite for this level of automation is having transparency over the current state, as well as having a standardized system of quality checks.
“We replaced the script that we used to replace ourselves with a button.”
As a result, we now have deployment on demand: whenever code is deemed ready, deployment is just a click away. Plus, and this is the most exciting part, everyone is able to deploy, since deployments are decoupled from the engineering team. Now, the code is automatically deployed to stage whenever a developer pushes changes to the main branch (this was also a process improvement). On stage, the PO can test the feature and do the live deployment – all by themselves, without any help from developers. Previously, all of this was done ping-pong-style between developers and PO, with one side always waiting on the other.
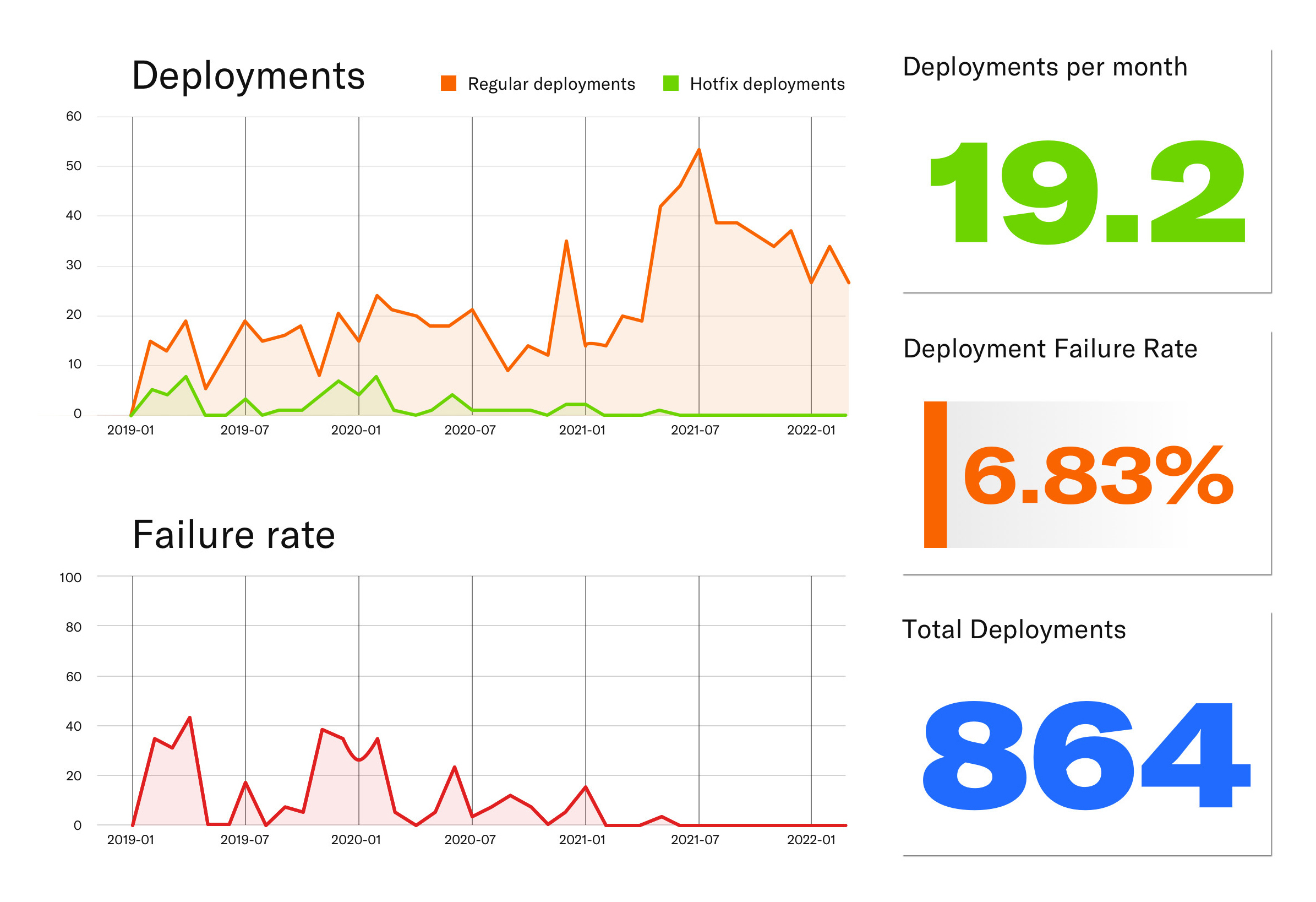
Using automation, we significantly increased the total number of deployments, while pushing the deployment failure rate to a minimum.
Automate, automate, automate
If you've made it this far, you'll know what’s coming: automate your deployment process as much as you possibly can – and spare yourself the trouble by doing so right from the beginning. Make deployment as easy as possible, so easy in fact, that even a product owner without a developer background can handle deployments to production. For us, automation increased the transparency in our deployment pipeline and saved countless working hours – time, which we can now put to better use building great things.
Beyond the effects on our deployment, automation had a number of effects on how we develop as a team. It brought us a long way toward implementing trunk-based development (you can read up on how that went here) with shorter production cycles and real continuous delivery. Plus, we had less work in progress on the whole, the psychological effect of which cannot be overstated. Never forget: people who finish things are more happy people.
If our story has inspired you to think more about your deployment set-up and increasing automation, you can get started by doing the DORA's DevOps quick check to see how you measure up. The DevOps research program also has some useful resources on everything from version control to continuous testing and delivery.
Finally, and this cannot be stressed enough, automating your deployment processes will lead not just to more stability and reliability in your deployment, but also to more stable and reliable software.
Christian Müllenhagen
Technical Director
christian.muellenhagen@turbinekreuzberg.com