
Deployment für Alle!
Wie wir unser Deployment automatisiert haben, um echte Continuous Delivery zu erreichen
24. Februar 2022 / Christian Müllenhagen

Im Laufe mehrerer Monate haben wir vollkommen verändert, wie wir das Deployment in einem unserer größten Plattformprojekte handhaben – sprich: wie wir »fertigen« Code für die Produktionsumgebung bereitstellen. Indem wir unser Deployment stark automatisiert haben, konnten wir echte Continuous Delivery implementieren. Dadurch kann jetzt praktisch jede Person, die am Projekt beteiligt ist, Code deployen – von Entwickler:innen über Product Owner bis hin zu allen Stakeholdern. Dabei sind nicht nur unsere Deployments selbst stabiler geworden, auch die Qualität unserer Software ist gestiegen.
Wahrscheinlich können die meisten Entwickler:innen von mindestens einem größeren Deployment berichten, das ein mulmiges Gefühl in ihnen ausgelöst hat. Nicht selten sorgt man sich vor unbeabsichtigten Folgen – und letztlich auch vor den Korrekturen, die danach erforderlich werden. Aus unserer Projektvergangenheit kenn wir das nur zu gut. Doch vor einigen Monaten haben wir uns auf den Weg gemacht, unser Deployment zu automatisieren und für alle Beteiligten einfacher und zuverlässiger zu gestalten.
Obwohl wir über ein ziemlich fortschrittliches Deployment-System mit Continuous Integration und einer ausgeklügelten Deployment Pipeline verfügten, war unser Ausgangspunkt nicht unbedingt optimal. Das System bestand aus manuellen Deyployments mit manuellen Checks. Nur eine kleine Gruppe von Kolleg:innen war tatsächlich in der Lage, Code zu deployen. Die meisten Entwickler:innen waren nicht selbst für das Deployment zuständig – wie die von ihnen entwickelten Features bereitgestellt werden sollten, kümmerte die meisten Kolleg:innen wenig. Um Vorfälle in Wochenendnähe zu vermeiden, waren Deployments nur bis spätestens Donnerstagmorgen erlaubt. Natürlich haben wir immer darauf geachtet, die Arbeit genau zu dokumentieren, um den Product Owner und die Stakeholder unseres Projekts so transparent wie möglich zu machen, was durchgeführt wurde.
Das Endergebnis war jedoch immer dasselbe: Unser Team sammelte große Mengen an Code an, die alle auf einmal deployt werden mussten. Dadurch war die Unsicherheit während und nach des Deployments immer am größten. Denn: Je mehr man auf einmal deployt, desto mehr kann schief gehen. Daran mussten wir etwas ändern.
Stufe 1: Mehr Transparenz im Deployment-Prozess
Als Erstes nahmen wir uns vor, den Deployment-Prozess für alle Beteiligten transparenter zu gestalten. Zu diesem Zweck erstellten wir eine klare Dokumentation für den Prozess selbst und teilten sie intern, damit alle Teammitglieder darauf zugreifen konnten. Dazu gehörte eine Checkliste mit sieben Hauptschritten von der Vorbereitung über die Stage bis hin zu Live-Deploys, inklusive ausdrücklicher Anweisungen, wie die Deployments erfolgen sollten und was in bestimmten Situationen zu tun ist, beispielsweise im Fall von Hotfixes oder Rollbacks.
»Große Mengen an Code zu deployen bedeutete, dass die Unsicherheit während und nach dem Deployment immer am größten war. Je mehr man auf einmal deployt, desto mehr kann schief gehen.«
Dies hatte zur Folge, dass das Deployment weniger von bestimmten Personen abhängig war. Mehr Teammitglieder waren in der Lage, Deployments selbst vorzunehmen, da die entsprechenden Schritte problemlos einsehbar waren. Das bedeutete, dass wir das Deployment optimieren und die Last aufteilen konnten. Mehr Standardisierung sorgte für deutliche Entspannung. Außerdem senkten wir unseren »Lottofaktor«: Sollte eine Schlüsselperson im Lotto gewinnen und schlagartig die Arbeit niederliegen, wären wir immer noch in der Lage, die Deployments in unserem Projekt zu stemmen.
Trotzdem gab es im Team noch deutliche Probleme im Umgang mit Deployments. Das lag vor allem daran, dass sich jede:r Einzelne nur selten darum kümmern musste. Führt ein Team von acht bis zehn Entwickler:innen täglich ein Deployment durch, dann ist jede Person höchstens einmal pro Woche an der Reihe. Sprich: Nur ein bedingt geeigneter Weg, um alle mit dem Prozess vertraut zu machen.

Stufe 2: Deployment über die Kommandozeile, plus Monitoring und Alerts
Allein die Tatsache, dass Menschen eine Checkliste von standardisierten Schritten zur Verfügung haben, ist natürlich keine Garantie dafür, dass alle sie immer korrekt ausführen. Um menschliche Fehler zu vermeiden gibt es nur einen Ausweg: Automatisierung. Deshalb begannen wir nun damit, unsere Deployments sukzessive zu automatisieren, um die Fehleranfälligkeit zu verringern und die Stabilität zu erhöhen. Nach und nach entfernten wir manuelle Schritte in unserem Deployment-Prozess – und ersetzten sie durch ein Skript. Von nun an sollte ein Kommandozeilen-Tool die Hauptlast übernehmen. Dies war eine fortlaufende Aufgabe, die wir Schritt für Schritt durchführten, indem wir jeden einzelnen Punkt aus unserer zentralen Dokumentation herauszogen und das Tool stetig erweiterten.
»Um menschliche Fehler zu vermeiden gibt es nur einen Ausweg: Automatisierung.«
Zudem implementierten wir ein Monitoring mit Hilfe von NewRelic und Grafana. Anstatt Statusmeldungen über Slack zu versenden, das Release Sheet auszufüllen und die bereitgestellten Jira-Tickets von Hand zu verschieben, wurde all dies durch Skripte erledigt. Wir richteten bestimmte Schwellenwerte ein, bei denen Fehler unser Alarmsystem auslösten, zum Beispiel wenn ein Fehler über einen bestimmten Prozentsatz von Seitenaufrufen oder eine bestimmte Zeitspanne anhielt. Von hier an galt nur noch "make deploy".
Dies führte zu einer sehr dynamischen Deployment-Situation. Die Anzahl der Deploys pro Woche (sogar pro Tag) nahm drastisch zu, wobei insgesamt viel kleinere Chargen gleichzeitig bereitgestellt wurden. Die Standardisierung nahm noch weiter zu, da der Spielraum für individuelle Interpretationen immer kleiner wurde, je mehr wir in das Skript integrierten. Schließlich brauchten wir viel weniger Zeit und Aufwand für die einzelnen Deployments. Wir fühlten uns so sicher in dem Prozess, dass wir nun auch freitags zu deployen anfingen.
Stufe 3: »PO-Deployment«
Und damit sind wir bei Phase 3 angelangt. Nach monatelangem Einsatz befinden wir uns nun an einem Punkt, an dem wir sogar das bewährte Kommandozeilen-Tool, das wir stetig erweitert hatten, in den Ruhestand schicken. Schließlich ist die Kommandozeile in der Regel nur für Entwickler zugänglich.
Also haben wir das Skript, mit dem wir uns selbst ersetzt haben, durch einen Button ersetzt. Wir haben die gesamte frühere Implementierung direkt in die Deployment-Pipeline von Jenkins verlagert. Jetzt gibt es einfach einen "RUN"-Button, mit dem man Deployments ausführen kann und der für alle zugänglich ist. Natürlich hat uns alles, was wir bis zu diesem Punkt getan haben, auf diesen Schritt vorbereitet. Voraussetzung für diesen Automatisierungsgrad ist die Transparenz über den jeweils aktuellen Zustand sowie ein standardisiertes System von Qualitätschecks.
»Wir haben das Skript, mit dem wir uns selbst ersetzen haben, durch einen Button ersetzt.«
Das Ergebnis ist ein bedarfsgesteuertes Deployment: Wenn der Code als fertig erachtet wird, ist seine Bereitstellung nur einen Klick entfernt. Außerdem – und das ist der spannendste Teil – sind nun alle in der Lage, das Deployment durchzuführen, da die Deploys vom Entwicklungsteam entkoppelt sind. Jetzt wird der Code automatisch auf ›Stage‹ bereitgestellt, wenn ein:e Entwickler:in Änderungen am Haupt-Branch vornimmt (auch dies war eine Prozessverbesserung). Auf Stage können POs die Features testen und das Live-Deployment durchführen – ganz allein, ohne technische Hilfe. Zuvor wurde all dies im Ping-Pong-Verfahren zwischen Entwickler:innen und PO durchgeführt, wobei eine Seite immer auf die andere warten musste.
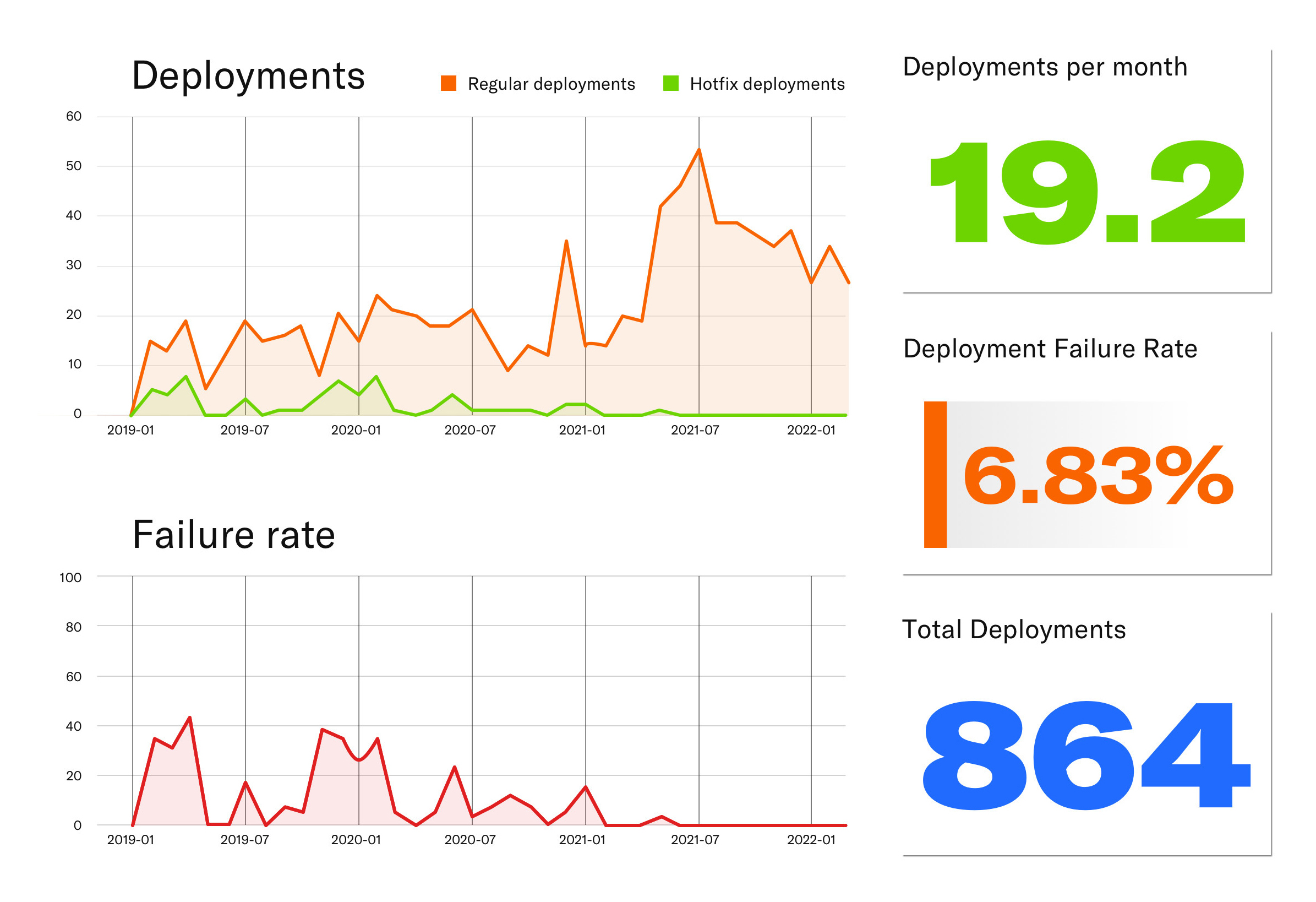
Durch Automatisierung haben wir die Zahl an Deployments stark gesteigert, während wir die Fehlerquote auf ein Minimum drücken konnten.
Automatisieren, automatisieren, automatisieren
Wer es bis hierher geschafft hat weiß, was jetzt kommt: Automatisiere deinen Deployment-Prozess so weit wie möglich und erspare dir ganz viel Ärger, indem du es gleich von Anfang an tust. Deployment sollte in der Durchführung so einfach wie möglich sein – sogar so einfach, dass ein:e Product Owner:in ohne großen Entwicklungshintergrund die das Deployen übernehmen kann. Für uns hat die Automatisierung die Transparenz in unserer Pipeline erhöht und unzählige Arbeitsstunden erspart – Zeit, die wir nun besser nutzen können, um großartige Dinge zu entwickeln.
Neben den Auswirkungen auf unser Deployment hat die Automatisierung auch die Art und Weise verändert, wie wir als Team zusammenarbeiten. Sie hat uns ein gutes Stück vorangebracht auf unserem Weg zu »Trunk-based Development« (wie das läuft kann man hier nachlesen) und damit zu kürzeren Produktionszyklen und echter Continuous Delivery geführt. Außerdem hatten wir insgesamt weniger unfertige Arbeiten, was einen nicht zu unterschätzenden psychologischen Effekt hat. Menschen, die Dinge zu Ende bringen können, sind schließlich auch glücklichere Menschen.
Wenn nun unsere Story dazu inspiriert hat, sich mehr Gedanken über Deployment-Abläufe und Automatisierung zu machen, dann bietet es sich an, einen Blick auf den DevOps Quick Check des DORA zu werfen. Dort lässt sich in einem ersten Schritt herausfinden, wie die eigene Organisation so abschneidet. Das DevOps Research Programm bietet auch einige nützliche Ressourcen zu einer Vielzahl an Themen von Versionskontrolle bis hin zu Continuous Testing und Deployment.
Letztlich kann es nicht oft genug betont werden: Sich mit Automatisierung von Deployment-Prozessen zu beschäftigen lohnt sich, weil es nicht nur mehr Stabilität und Zuverlässigkeit in das Deployment an sich bringt, sondern auch zu stabilerer und zuverlässigerer Software führt.
Christian Müllenhagen
Technical Director
christian.muellenhagen@turbinekreuzberg.com