KI in der Praxis
Wenn Innovation ruft, lassen wir alles stehen und coden.
Die Hackout ist für uns bei Turbine Kreuzberg ein jährliches Highlight. Wir kommen als Team zusammen und widmen uns abseits des Tagesgeschäfts hauseigenen Herzensprojekten. Dieses Jahr haben wir den Fokus auf KI gelegt, um frei von unserem Projektanforderungen zu experimentieren und Neues zu wagen. Unsere beiden Standorte in Berlin und Faro haben innerhalb von zwei Tagen beeindruckende KI-Konzepte entwickelt - von spannenden Prototypen bis hin zu konkreten Use Cases.
Trung Quang Dang / 27.01.2026

1. Try On Studio – eine KI-gestützte virtuelle Umkleidekabine
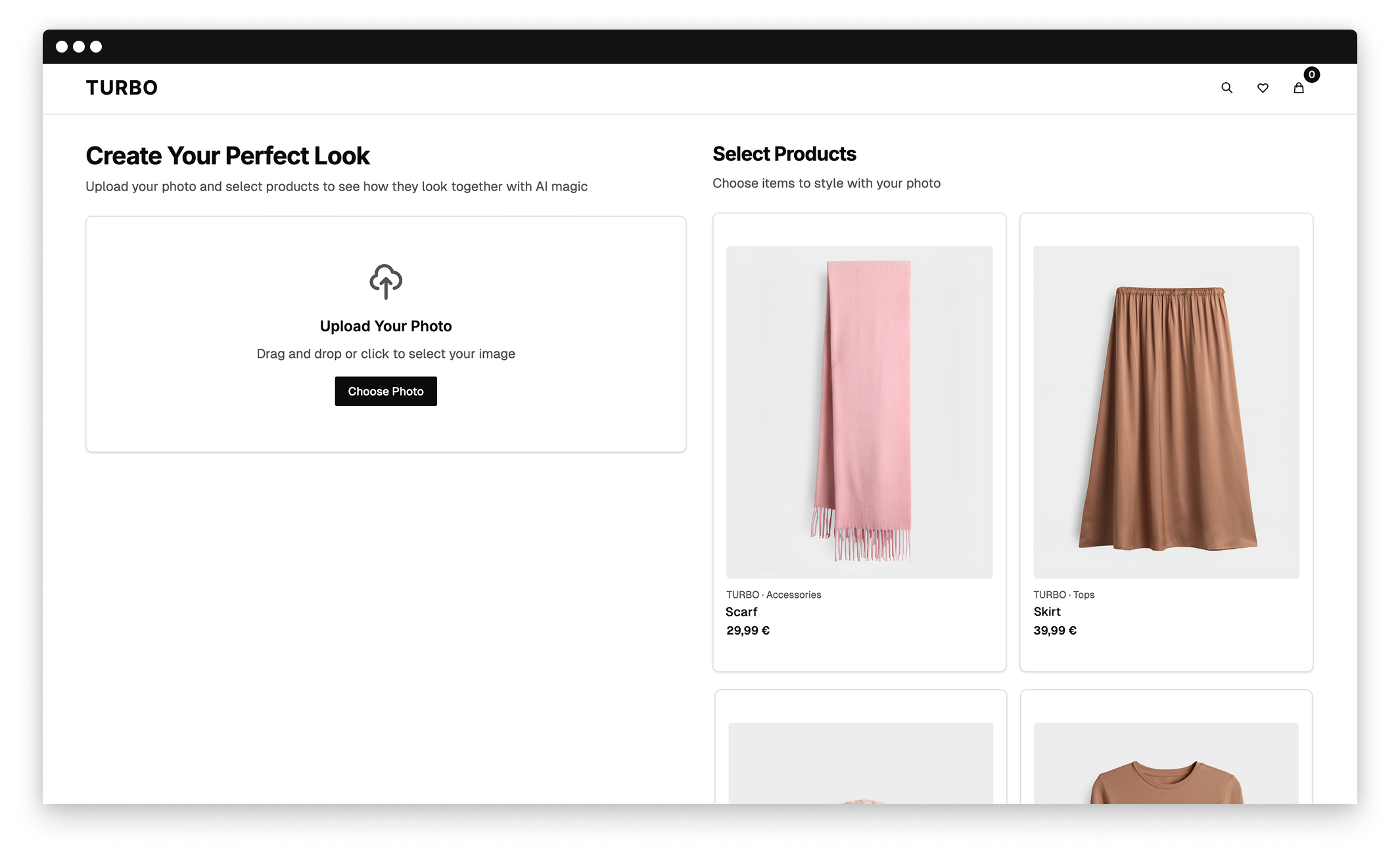
Wir alle kennen das: Ein Kleidungsstück wird online bestellt, geliefert, anprobiert – und passt einfach nicht so wie auf den professionellen Fotos. Also geht es zurück. Das Problem: Kund:innen können erst nach der Lieferung beurteilen, wie die Kleidung tatsächlich an ihnen aussieht. Die Folge sind hohe Retourenquoten im Fashion-E-Commerce.
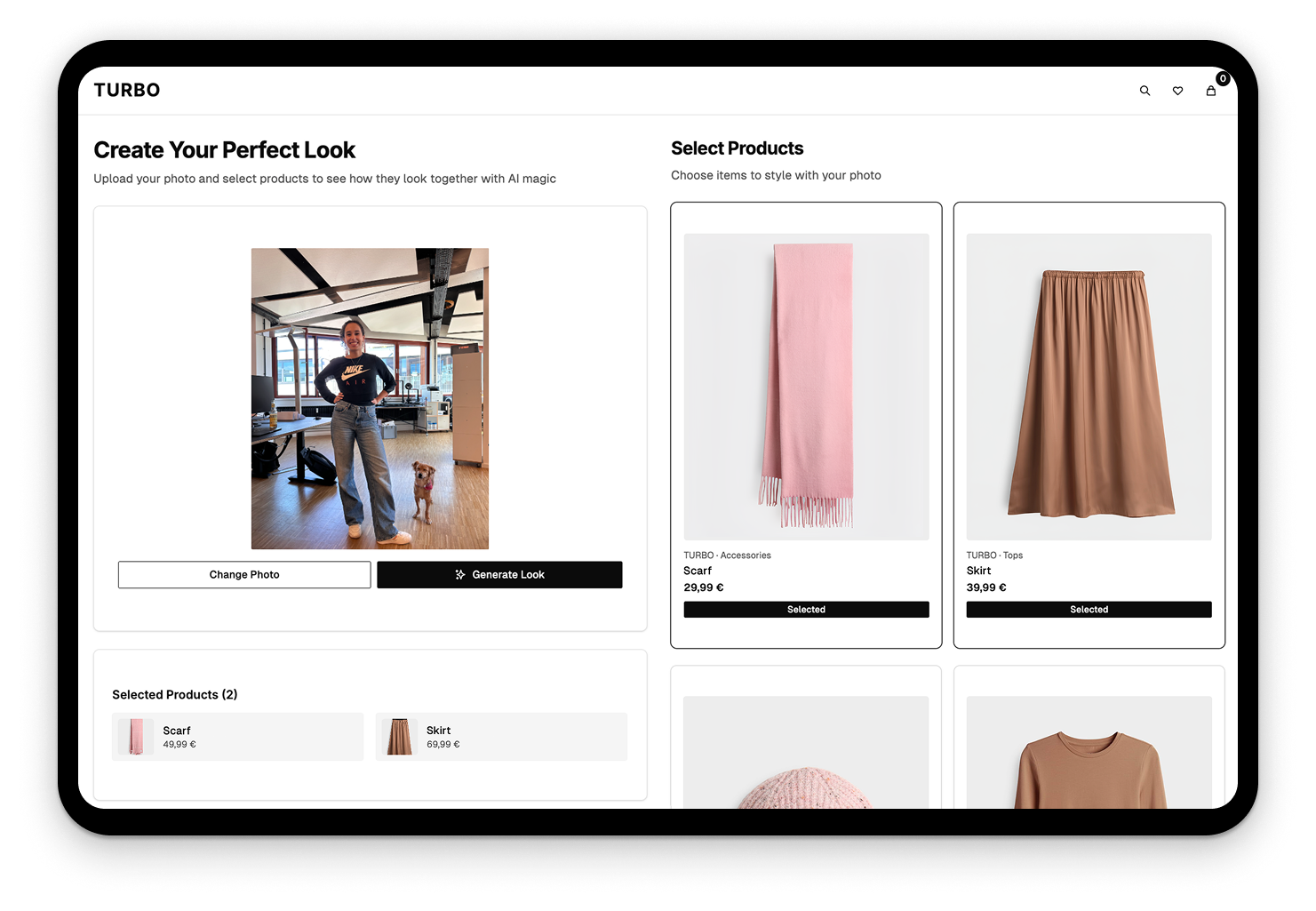
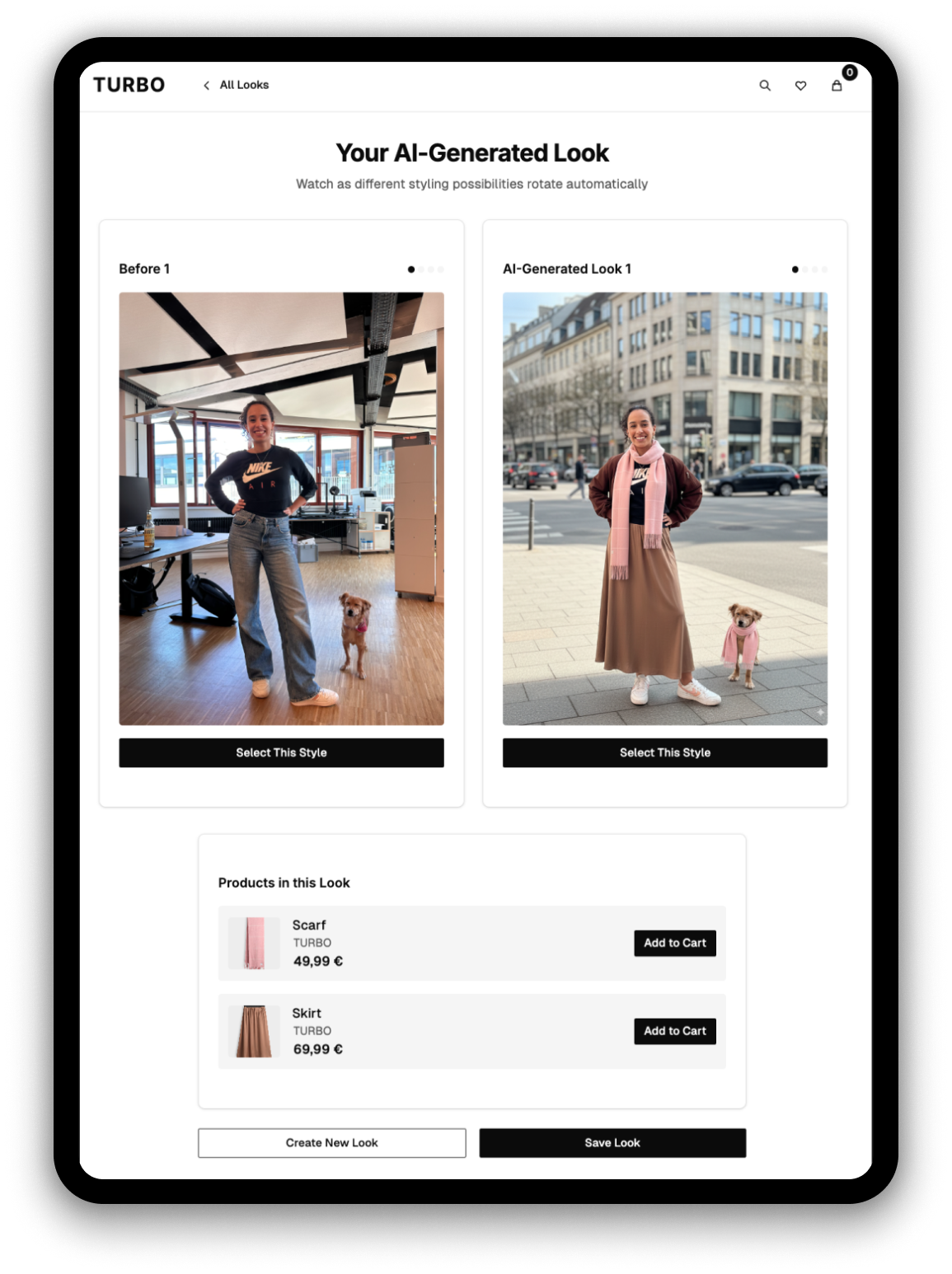
Für dieses Problem hat unser „Try On Studio“-Team einen Lösungsansatz entwickelt, der generative KI nutzt. Kund:innen wählen einen oder mehrere Artikel aus und laden ein eigenes Foto hoch. Die KI kombiniert die Produkte mit dem Bild und ermöglicht so eine virtuelle Anprobe. Das Ergebnis: Kund:innen können sich bereits vor der Bestellung ein realistisches Bild machen - ohne physische Anprobe, ohne Lieferung.
Das „Try On Studio“-Team nutzte v0 von Vercel, um in kürzester Zeit und mit minimalem Entwicklungsaufwand eine funktionale Mock-Up-Applikation zu erstellen, die die Customer Journey beispielhaft darstellt. Für das Team lief es während der Hackout nach dem Motto „so far, so good“. Die größte Herausforderung war die Bildgenerierung selbst: Zwar übertraf die KI die Erwartungen in puncto Bildqualität, doch die Produkte ließen sich nicht immer zu 100 % korrekt darstellen und Gemini hatte Schwierigkeiten, die Gesichter der Personen originalgetreu zu übernehmen. Um dennoch die bestmögliche Qualität zu gewährleisten, wurde die Bildgenerierung sequenziell durchgeführt.
Das „Try On Studio“-Team sieht großes Potenzial für den Einsatz im digitalen Fashion-Handel. Denn jede Retoure kostet. Versand, Logistik, Prüfung, Wiederaufbereitung – Fashion-Händler kämpfen mit Retourenquoten zwischen 20 und 50 Prozent. Virtuelle Anproben können diese Quote messbar senken. Weniger Retouren bedeuten niedrigere Logistikkosten, weniger gebundenes Kapital in zurückgesendeter Ware und zufriedenere Kund:innen, die beim ersten Mal das Richtige bestellen. Die rasanten Fortschritte bei KI‑Bildgeneratoren zeigen: Die Qualität steigt kontinuierlich und erfüllt die Anforderungen immer besser. Für den digitalen Modehandel ist klar: Virtuelle Anproben kommen – es ist nur eine Frage der Zeit.

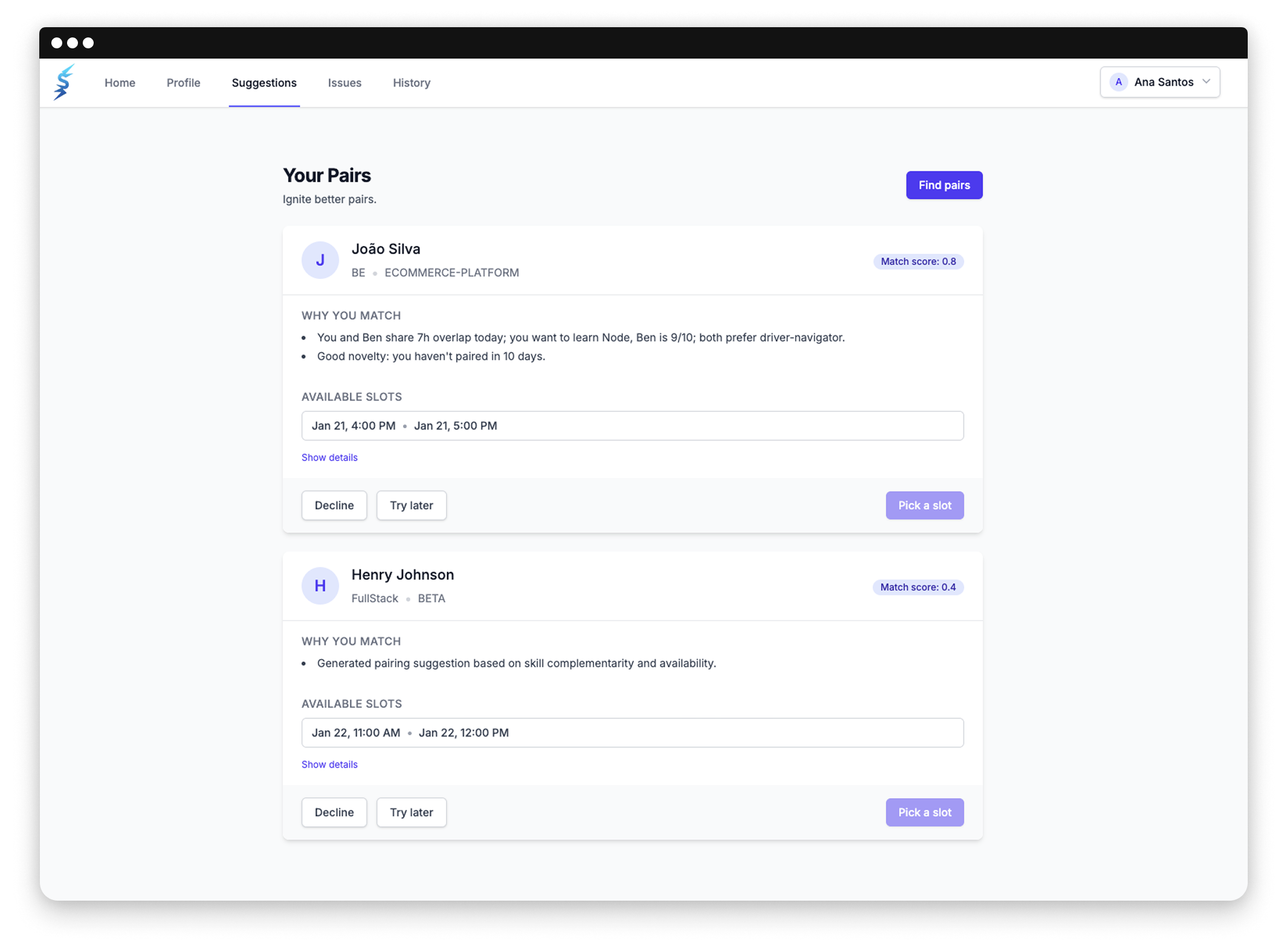
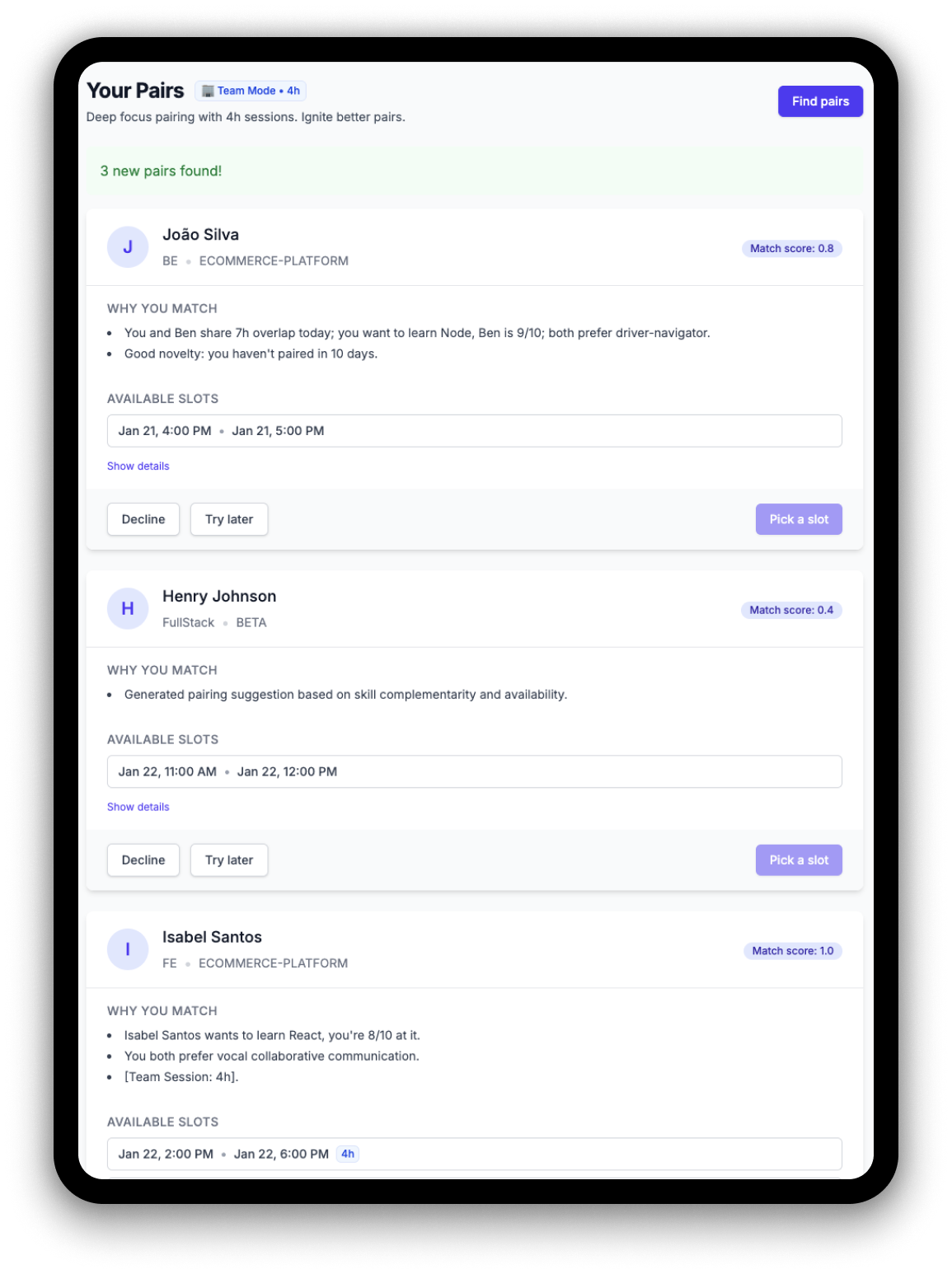
2. PairSpark – intelligentes Teamfinding für Entwickler:innen
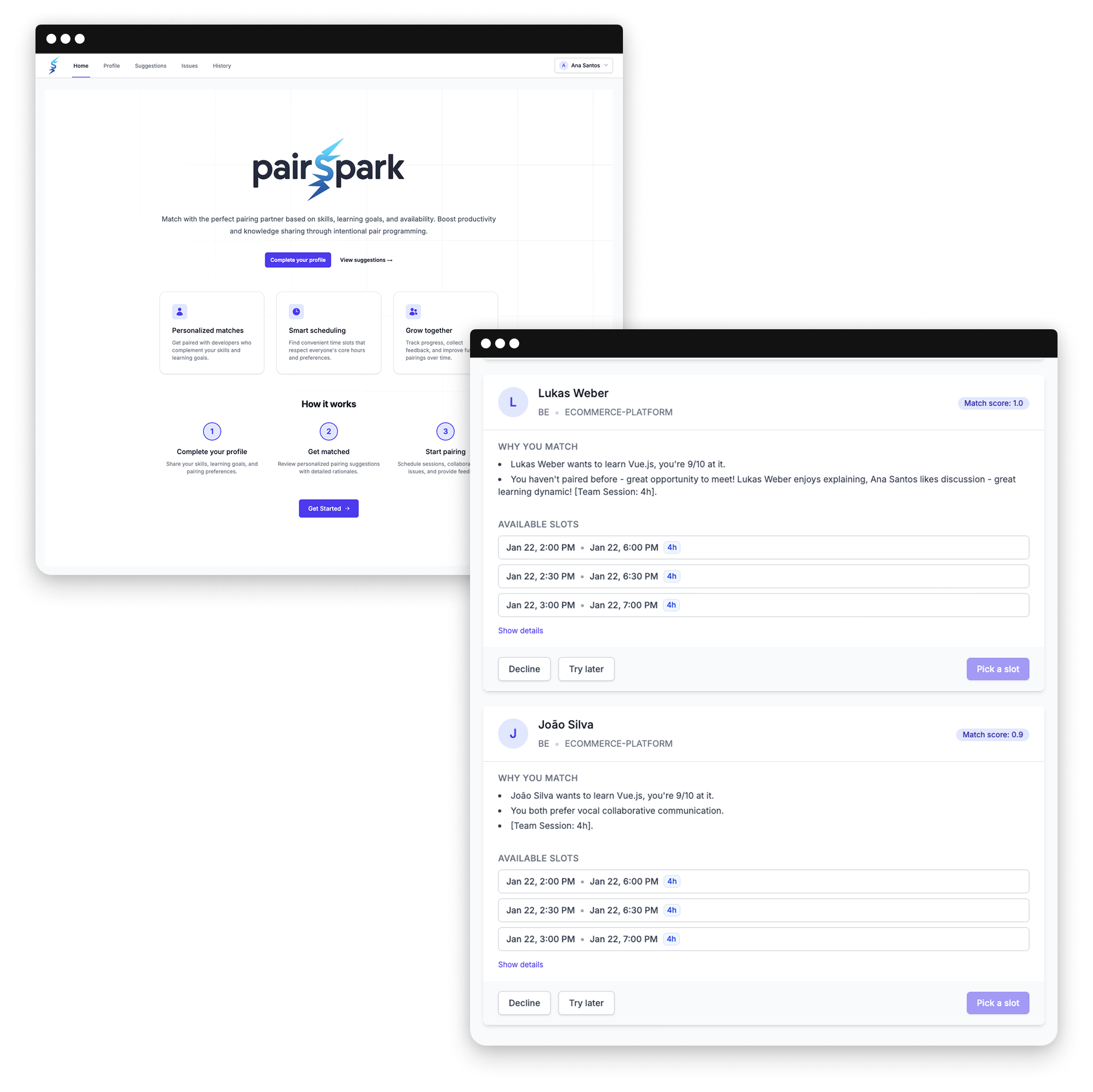
In den meisten Entwicklungsteams entstehen gewohnheitsmäßige „Komfort-Pairings“ – man arbeitet mit denselben Personen zusammen, weil es vertraut und effizient ist. Diese eingefahrenen Muster begrenzen jedoch Kollaboration, Wissensaustausch und Innovation. Erst wenn Kolleg:innen im Urlaub sind und Teams sich neu organisieren müssen, zeigt sich: Neue Pairings bringen frische Perspektiven und funktionieren überraschend gut. Die Hürde liegt nicht am fehlenden Willen zur Veränderung, sondern an der Unsicherheit: Mit wem passe ich zusammen? Wer kann mir bei meinen Lernzielen helfen?
Das „PairSpark“-Team entwickelte ein intelligentes Matching-Tool, das Entwickler:innen gezielt mit idealen Pairing-Partnern zusammenbringt. Nutzer:innen erstellen ein Profil mit ihren Arbeitspräferenzen, technischen Skills und Lernzielen. Ein Algorithmus analysiert diese Profile und schlägt passende Partner vor – mit konkreten Begründungen: „Diese Person beherrscht das Framework, das du lernen möchtest“ oder „Ihr habt noch nie zusammengearbeitet – eine Chance für neue Impulse“. Direkt aus der Plattform heraus lassen sich Pairing-Sessions planen. Das Ergebnis: Intentionale Pairings werden einfacher, dynamischer und fördern eine kollaborative Teamkultur.
Die größte Herausforderung lag in der Konzeption des Matching-Systems. Ursprünglich sollten Nutzer:innen ihre Präferenzen frei formulieren können. In der Praxis zeigte sich jedoch: Freitexte lassen sich nicht sinnvoll matchen. Das Team entwickelte ein strukturiertes System mit vordefinierten Optionen – etwa zu bevorzugten Arbeitsstilen oder technischen Schwerpunkten. Diese Anpassung verbesserte die Matching-Qualität erheblich. Eine weitere Anforderung: Die Plattform muss sowohl für interne als auch externe Entwickler:innen zugänglich sein, da viele Teams gemischt arbeiten.
PairSpark adressiert Wissenssilos und starre Arbeitsstrukturen in Entwicklungsteams. Durch intelligentes Matching wird Fachwissen gezielt verteilt, Innovation gefördert und die Teamdynamik gestärkt. Statt manueller Koordination übernimmt das Tool die datenbasierte Empfehlung passender Pairing-Partner – besonders wertvoll in gemischten Teams aus internen und externen Entwickler:innen.
Geplante nächste Schritte umfassen die Implementierung von Google OAuth für sichere Authentifizierung, die Integration mit Jira für datenbasierte Pairing-Empfehlungen anhand offener Tickets und verwendeter Technologien sowie erweiterte Slack-Benachrichtigungen. Langfristig soll das Tool auch Mob Programming unterstützen und dynamische Gruppenbildung für Sessions mit drei oder mehr Entwickler:innen ermöglichen.


3. CRAG FTW – interne Wissensbeschaffung, auch für nicht-technische Teams
In Softwareprojekten verteilt sich Wissen über zahlreiche Quellen: Code-Repositories, Git-History, Jira-Tickets und Confluence-Dokumentationen. Projektrelevante Informationen aus diesen verschiedenen Systemen zusammenzutragen, ist für nicht-technische Teammitglieder wie Product Owner, Agile Coaches oder Sales-Teams eine Herausforderung. Selbst für Entwickler:innen bedeutet die Suche über mehrere Plattformen hinweg einen erheblichen Zeitaufwand. Dadurch entstehen Wissensinseln, ineffiziente Kommunikation und verzögerte Entscheidungen.
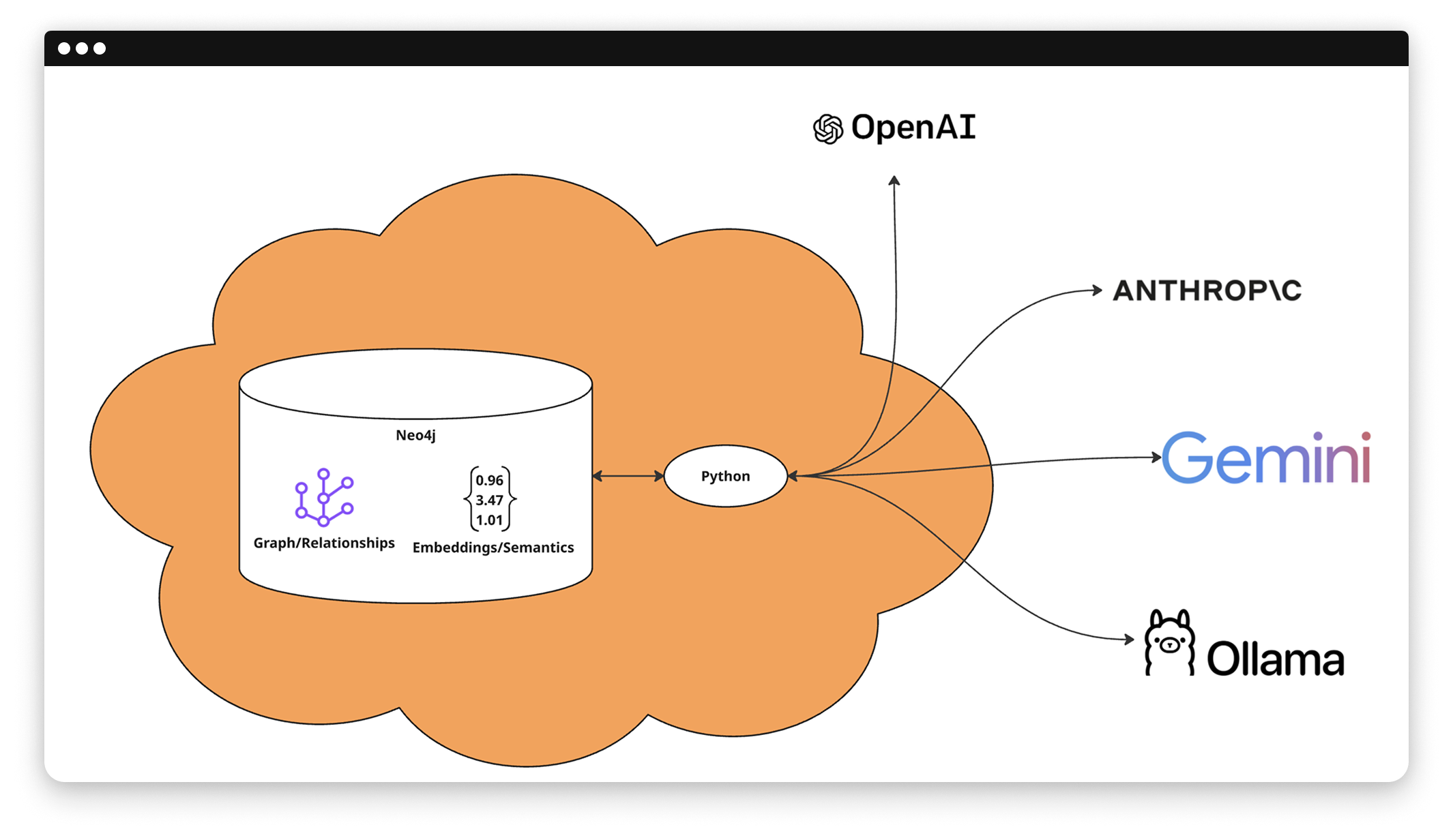
Das CRAG-FTW-Team entwickelte eine intelligente Wissensdatenbank, die Informationen aus Source-Code-Repositories, Git-History, Jira-Tickets und Confluence kombiniert und über einen KI-gestützten Assistenten zugänglich macht. CRAG steht für Corrective Retrieval Augmented Generation – ein Ansatz, der deutlich präziser arbeitet als herkömmliche RAG-Systeme. Die Besonderheit: Das System nutzt eine Graph-Datenbank, um Zusammenhänge zwischen verschiedenen Datenquellen zu erkennen und kontextbezogene Antworten zu liefern. Ein Product Owner kann so etwa fragen: „Welche Features wurden im letzten Sprint umgesetzt und welche technischen Abhängigkeiten bestehen?“ – ohne selbst Code lesen oder durch Dutzende Tickets navigieren zu müssen.
Die größte Hürde war die API-Limitierung von OpenAI beim Einlesen großer Datenmengen – besonders während der Hackout, als viele User gleichzeitig auf das System zugriffen. Der Prozess wurde dadurch deutlich verlangsamt und fehleranfällig. Eine weitere Herausforderung: Projekte mit sehr großen Ticket-Mengen sind kostenintensiv und zeitaufwendig zu verarbeiten. Das Team arbeitete daran, das Gesamtsystem in einem Docker-Container transportierbar zu machen, um es auf unterschiedlichsten Betriebssystemen einsetzen zu können. Trotz dieser Hürden: Das Gesamtsystem funktioniert und lässt sich bereits gut anwenden.
CRAG FTW demokratisiert den Zugang zu Projektwissen. Nicht-technische Teammitglieder erhalten erstmals direkten, verständlichen Zugriff auf technische Projektinformationen – ohne Entwickler:innen als Übersetzer zu benötigen. Das beschleunigt Entscheidungsprozesse, verbessert die Kommunikation zwischen Teams und reduziert Abhängigkeiten. Für Sales-Teams bedeutet das: schnellere, präzisere Antworten auf Kundenanfragen zum Projektstatus. Für Product Owner: fundierte Entscheidungen auf Basis aktueller technischer Gegebenheiten. Die nächsten Schritte umfassen die Optimierung der Datenverarbeitung für große Projekte, die Reduzierung von API-Kosten und die vollständige Produktionsreife des Systems.




4. Turbine Translator AI – optimierte App-Übersetzungen auf Knopfdruck
Die Übersetzung digitaler Anwendungen ist zeitaufwendig, fehleranfällig und meist manuell. Entwickler:innen und Product Manager müssen Übersetzungsschlüssel pflegen, verschiedene Sprachen koordinieren und dabei konsistente Terminologie sicherstellen. Besonders bei Multi-Projekt-Umgebungen oder Agenturen mit mehreren Kunden wird die Verwaltung schnell unübersichtlich. Neue Sprachen hinzuzufügen bedeutet oft: hunderte Übersetzungen manuell erstellen oder externe Dienstleister beauftragen – beides kostet Zeit und Geld.
Das Turbine-Translator-AI-Team entwickelte eine Plattform, die den gesamten Übersetzungsprozess automatisiert. Nutzer:innen erstellen „Anwendungen“ innerhalb der Plattform, jede mit eigenem API-Token und konfigurierbaren Sprachen. Für jede Anwendung werden Glossare mit Übersetzungsschlüsseln verwaltet – die KI übersetzt diese per Knopfdruck in alle gewünschten Sprachen. Das Besondere: Nutzer:innen können Kontext für bessere KI-Ergebnisse bereitstellen, Übersetzungen manuell nachbearbeiten und über eine API direkt in ihre Anwendungen integrieren. Ein Produktkatalog wird so etwa als „Product Category“-Key angelegt und automatisch in alle konfigurierten Sprachen übersetzt – mit vollständiger Versionierung und Diff-Vergleich, ein Vorgang, um die Unterschiede zwischen zwei Dateien zu finden.
Die größte Herausforderung waren Layout-Probleme mit Windsurf bei der Code-Generierung, da die Genauigkeit der KI-Vorschläge manchmal schwankte. Das Team musste hier manuell nachsteuern. Eine weitere Anforderung war die Implementierung eines Approval-Prozesses: Übersetzungen von Langdock müssen vor der Freigabe geprüft werden können. Die Plattform funktioniert zudem nicht isoliert, sondern ist auf die Integration mit anderen Anwendungen über API-Keys ausgelegt – diese Architektur erforderte sorgfältige Planung der Datenübertragung und Authentifizierung.
Turbine Translator AI beschleunigt Projekt-Deliveries erheblich und reduziert manuelle Übersetzungsarbeit auf ein Minimum. Die zentrale Verwaltung sorgt für konsistente Terminologie über Projekte und Sprachen hinweg. Besonders wertvoll: Die rollenbasierte Zugriffskontrolle macht die Plattform ideal für Agenturen mit mehreren Kunden. Entwickler:innen profitieren von einfacher API-Integration, Product Manager von schneller Anpassung unterstützter Sprachen. Geplante Features umfassen ein Widget für Inline-Editing – um Übersetzungsschlüssel direkt in der Anwendung zu identifizieren und zu bearbeiten – sowie automatische Checks für veraltete Translation-Keys, die nicht mehr verwendet werden. Mit weiteren Feature-Erweiterungen ist die Plattform bereits für den Einsatz in eigenen Projekten nutzbar.
Unsere KI Tools











Fazit der Hackout
Die Hackout 2025 hat gezeigt:
Wenn Innovation ruft, lassen wir alles stehen und coden. Innerhalb von zwei Tagen entstanden mehrere funktionsfähige Prototypen, die reale Probleme adressieren: von Retourenquoten im Fashion-Handel über Wissenssilos in Entwicklungsteams bis hin zu manuellen Übersetzungsprozessen.
Was wir dabei gelernt haben? KI-gestützte Coding-Tools wie Cursor, Windsurf und Langdock beschleunigen die Prototypenentwicklung massiv. Was früher Wochen dauerte, entsteht heute in Tagen. Gleichzeitig haben wir gesehen, wo KI heute noch an ihre Grenzen stößt – bei der Bildgenerierung, bei API-Limits oder der Genauigkeit von generiertem Code. Und genau diese Erkenntnisse sind genauso wertvoll wie die Prototypen selbst.
Die Hackout ist nicht nur ein Weg, uns mit neuen Technologien vertraut zu machen. Sie bringt Kolleg:innen aus Berlin und Faro zusammen, die vorher nie gemeinsam an Projekten gearbeitet haben. Neue Perspektiven, frische Impulse und direkter Austausch, um innovative Ideen umzusetzen – genau das, wofür wir die Hackout schätzen.
Bereit für KI? Wir auch
Lassen Sie uns über Ideen, Herausforderungen, Bedürfnisse und Lösungen sprechen.

- Matthias Gronwald
- Co-CTO
- matthias.gronwald@turbinekreuzberg.com