
Turbine goes: XPOMET Health Hackathon 2019
10/15/2019 – Stefan Adolf

Hackathon #7 this year introduced me to the unknown waters of health tech & machine learning. I’ve always tried to get myself into these areas, so I’m glad I finally have been forced to wrap my head around them. The organization team (thank you impactfarm for making it outstanding) told us four weeks in advance about the challenge they had in mind for us — and thankfully they also came up with a team name: From September 14 on, we could refer to ourselves as the “Turbiners” (which is slightly incorrect, since two of us were absolutely unaffiliated with Turbine). So, we had four weeks of time preparing our project — which is still hard when you’re on a full-time job — and it read: “intelligent claim management in the digital health ecosystem”.

Now, what you may not be aware of: Fraud is a highly underrated and very relevant topic in the health industry. According to a McKinsey study from 2017 there’s a saving potential for health insurers in Germany of up to half a billion euros a year — only by checking reimbursement claims by care providers (doctors, hospitals, hospices etc.) more thoroughly. As it turns out, 70% of all claims need to be checked, but only 8–10% of the potentially fraudulent cases are finally identified and corrected. If that doesn’t sound like a good case for Machine Learning, what does?

Since our team had been assembled quite randomly, we were extraordinarily lucky to have had Elena Williams in our team. She’s currently studying data science in Hamburg and could contribute much of her knowledge into our project. Around two weeks before the hackathon we were looking for data sets that could help us and eventually Elena came up with this one. It contains 130.000 claims by more than 5400 providers and has been examined by experts who identified the fraudulent entries. What’s important to understand: Fraud can only be observed on a provider level. The unique claims are pretty much unobtrusive, so any model we could come up with only would operate on providers and never on particular claims.
„So how do you feel on the second day of the #healthhackathon19, Elena?!“ pic.twitter.com/Bl8n4RRMXR
— Bayer Karriere (@BayerKarriere) October 11, 2019
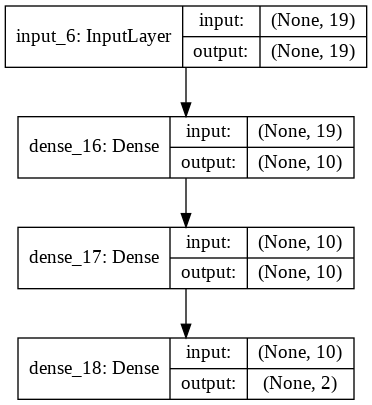
The original notebook takes three approaches to analyse the dataset: Logistic Regression, Random Forest Classifiers, support vector machines and an auto encoder. They reached a predictive accuracy of anything between 50–90%. To boost the accuracy further, Elena tried to figure out better features to train the model and relied on a Keras Deep learning model with four layers. According to the training evaluation she reached an accuracy of 93% in the end which is quite outstanding.
In the meantime, the rest of the team concentrated on making the prediction model usable — seeing is believing, right? So I created a fresh React app, imported all the test data into a Sqlite database (sic) and wrote a Flask micro API that’s capable of selecting all claims for a given provider. It also comes with an endpoint to call the predict function of the trained model. I noticed quite early that this is not a simple task: All these data scientists use their highly interactive Jupyter notebooks for one reason or another, but that’s not something that you want to build a “reliable” service on (do you?). So most of our backend work consisted in transferring Elena’s data transformation and feature extraction code into a plain Python backend.
The plan was to upload an Excel / CSV-file with a batch of beneficiary / claim data on the frontend, translate it into the presentation that Elena’s model would expect and run the prediction on it. Thankfully our junior dev Sascha took care of the upload part, so I could concentrate on the integration. I made one observation that could be helpful for others: While Sqlite comes with great support of automatic CSV imports it unfortunately translates a string value of “NaN” to “NA” (which might be the NaN-representation of Sqlite, who knows). When reading this data with Pandas again, it interprets it as string. Once we figured that out, following up the other 250 cells was close to a piece of cake. Python people might know that but let me repeat: The tensor manipulation features of Panda’s DataFrame are simply outstanding! If you happen to do any data analysis in any language — stop here and switch to Python, it will save you days of data manipulation.
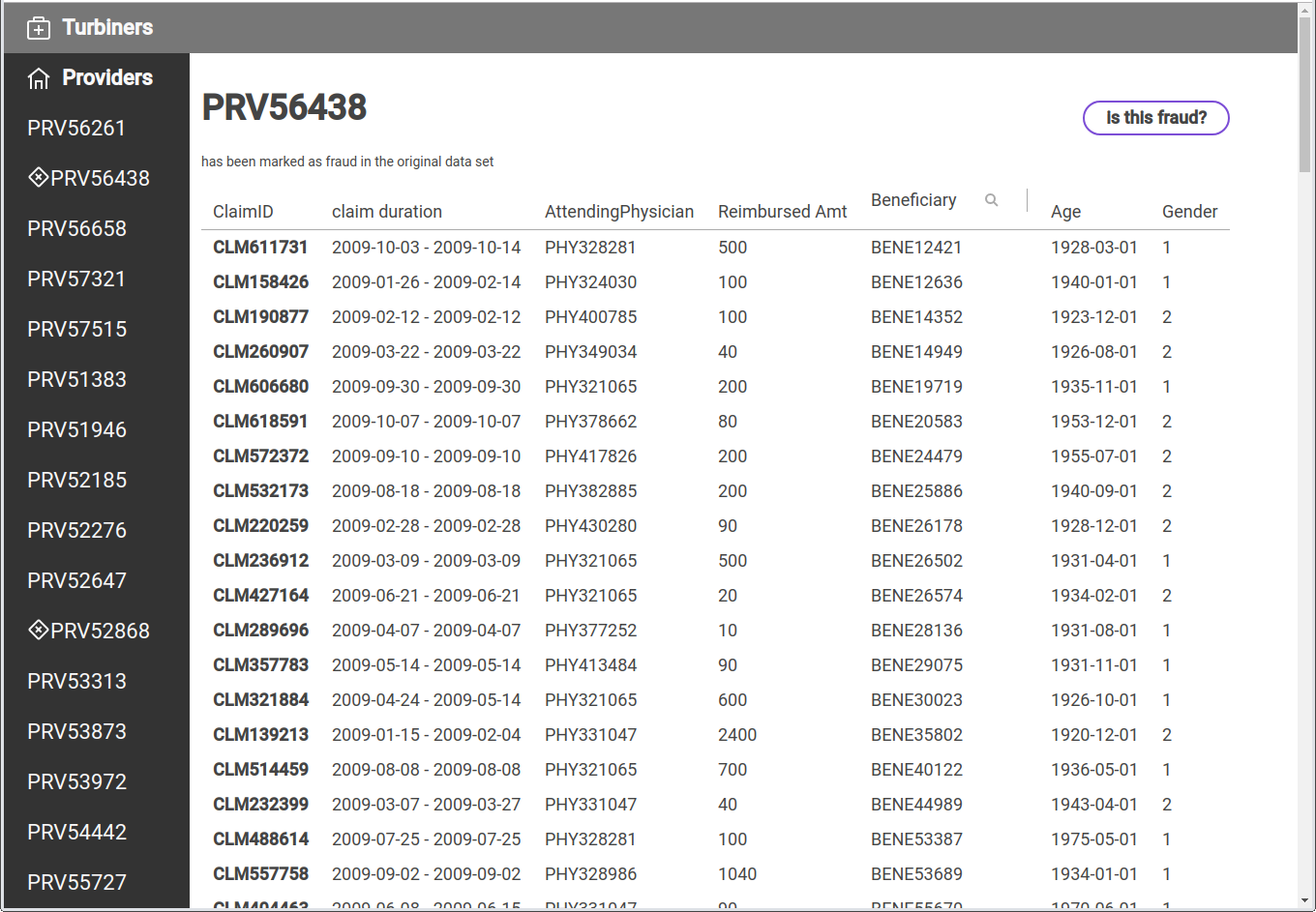
A major issue we weren’t able to figure out is the scaling of predicted values. Elena’s model performed nicely on training and testing data sets but calling the prediction on a single data set (consisting of around 60 claims, derived from the original training data) just ended up in an array of unusable float data — in the end, she didn’t develop a binary classifier, but rather a predictor that yields a certain probability of having identified a fraud. Unfortunately, without a clear output it wasn’t possible for us to demonstrate our model’s accuracy, but I’m pretty sure that’s mainly due to our missing experience.
If you’d just like to get a feeling for all achievements, here is a deployment for you (it’s currently asleep, give it 30 seconds to wake up & another 20 seconds to download the database from my S3 bucket): turbiners.netlify.com. The codebase is split into a Python backend and a React frontend. It looks so nice because I’ve been using Grommet JS for styling.

Another part of the jury’s evaluation was a business model canvas for our case. Now, since I’m a down-to-earth, glue-level, hard rock listening developer I must admit that my business development skills have degraded and I still have the strong opinion that “business” and “hackathon” are never a good match. I’ll still share a few of our ideas and would like to thank Florian Schulze, Turbiners’ team member #4 for the effort he took from our shoulders by starting off ideas:
- Value proposition: we want to build a digital claim management service (running on our side) and an obfuscator / anonymizer service (running on the insurance / client’s side).
- Our key partners would be insurance auditors with lots of experience in detecting medical claim fraud cases.
- Our primary customer segments would be German health insurance companies and their attached consultancies.
- As sales channels we identified health conferences and SaaS solution marketplaces (e.g. offering a blackboxed service instance of us on customer operated dedicated AWS instances).
- After quite some discussion, we agreed that our preferred business model would be to take a 0.5% share of all analysed claim reimbursements files (which could add up to around €50–100mn revenue / year depending on quality of prediction and market share)

Some miscellaneous takeaways and side notes
- The winning team (consisting of only 1 member) in our category has absolutely earned his prize: He threw together an Android app, a Blockchain, a VR channel and MongoDB and built an app that first tells you which exercise to execute and then scans your body movements to identify that you’re doing it right. Once done, it stores your achievement on a chain and registers your activity in Mongo. I’m dead sure that it took most of the four weeks of preparation to put all these pieces together, and I was quite impressed by his demo.
- The other category dealt primarily with machine support in “real” health applications, e.g. ophtomal… eye diseases. One team certainly stood out: They used some weird looking lens concept to scan your eyeball. With a little machine learning / image classification attached, they were able to identify major health conditions within just a fraction of the costs a “real” medical device would need.

Contacts and Takeaways
The most important reason why I personally wanted to join the health hackathon, though: I’ve been looking for contacts, inspiration and validation of the real world use case I’m currently working on at Turbine. That is: storing a patient’s medical record and its access rights on a decentralized ledger. And I have not been disappointed:
Several parties, among them four co-workers of Berlin’s Charité, lawyers, doctors and consultants strongly confirmed my assumption: There is absolutely nothing like a shared digital patient file in Germany. All approaches toward it are heading into the direction of either medication plans, fitness tracking or “eGK” applications that collect and store data that a patient collects himself (e.g. by tracking her blood pressure). It’s astonishing, but every time I roughly illustrated our idea everybody became very excited and immediately offered their full support.
Conclusion
This is what a conference and hackathon should look like. The food could’ve been better (no complaints about bad food if it’s for free, yes, I’m already sorry), the beer could’ve been more plenty, the surround sound of all four conference panels could’ve been less annoying and the unnecessary artificial “pressure” that the main hackathon sponsors have been building up upfront was unnecessary. But besides that, we all had a lot of fun! :) Next up: Diffusion 2019!
